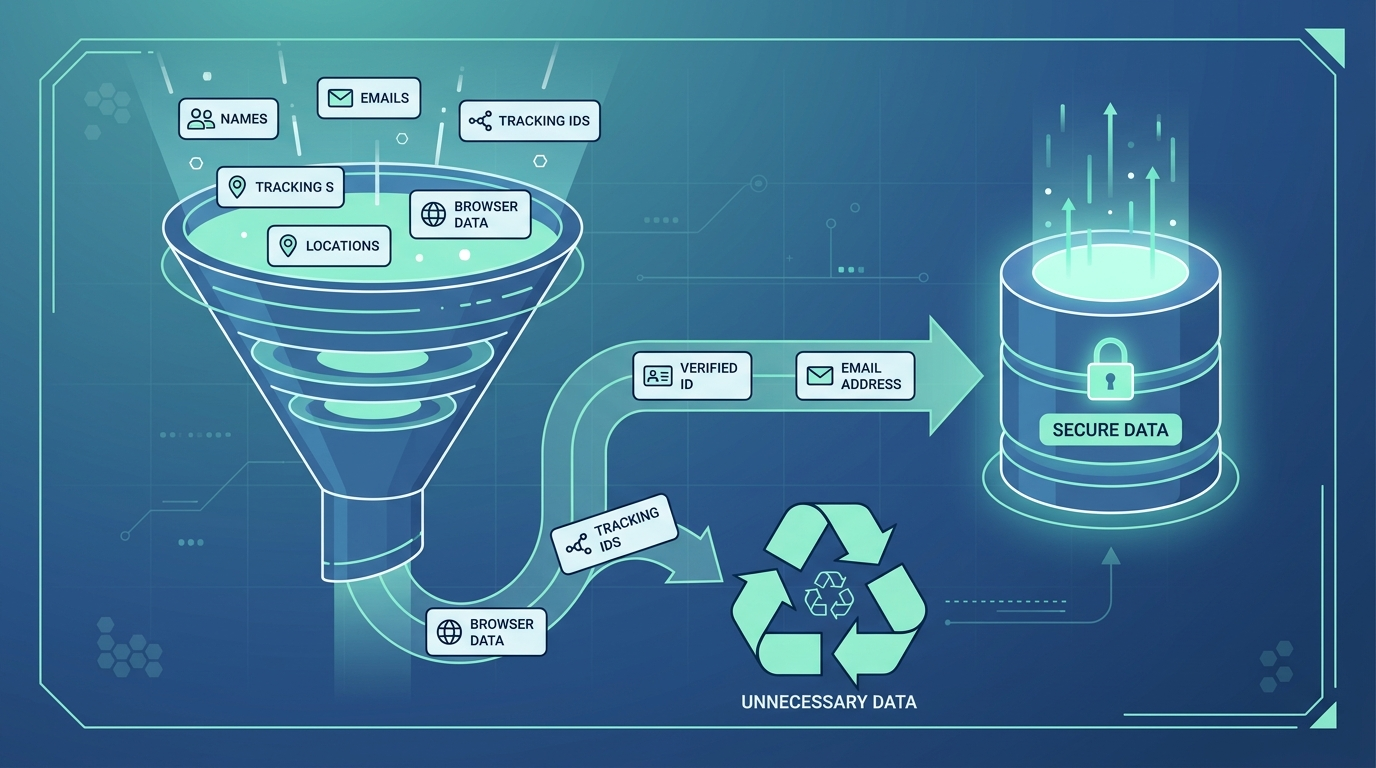
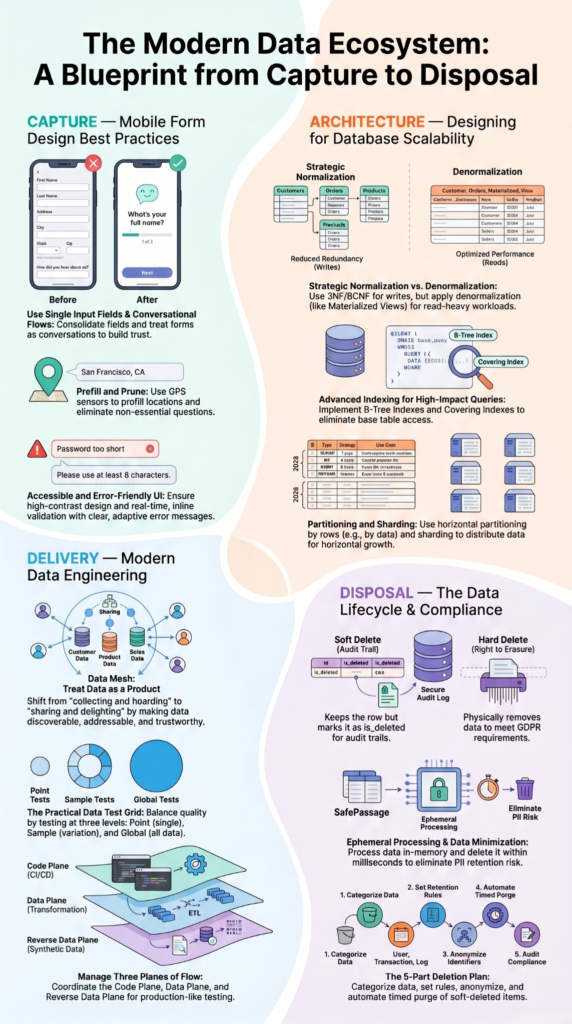
Data minimization principles software helps developers collect and retain only the data needed for a specific purpose. It reduces privacy risks, lowers storage costs, and limits the impact of data breaches. Rather than treating minimization as a compliance task, teams should build it directly into their applications through Secure Coding Practices.
This guide explains practical ways to apply data minimization across software design, development, and operations. Keep reading.
Quick Wins: What Developers Should Know About Data Minimization First
Forget the compliance seminars. Here’s what actually works on Monday morning:
- Question every single data field. If you can’t point to a specific feature that breaks without it, don’t collect it.
- Set a deletion date for everything. Customer records, log files, analytics events all need an expiration.
- Anonymize data the moment it enters your system if you only need it for trends, not individual details.
- Stop using “soft deletes” as a permanent solution. They’re a staging area, not an archive.
What Are the Core Data Minimization Principles in Software?
The core principles of data minimization are straightforward in theory, but applying them means we, as developers, have to look at every piece of information through three filters.
First, is the data adequate? We ask if it’s truly enough for the task. Requesting a phone number when you only need an email is excessive, and we see this overreach all the time in spec reviews.
Next, is it relevant? There needs to be a direct, logical link to the software’s purpose. In our training, we use the classic example of a weather app asking for a user’s gender; it fails this test immediately.
The final and strictest filter is limitation. This is where we have to push back. The rule is to collect only what is strictly necessary, rejecting “nice-to-have” or “just-in-case” data. We’ve learned from experience that vague product requests are where most data bloat starts.
Research from ACM Digital Library shows
“Lack of consistent data minimization standards or an understanding of the principle among software developers” – ACM Digital Library
Why Does Data Minimization Matter Beyond Compliance?
Sure, avoiding GDPR fines is a good motivator. But the real, tangible benefits of data minimization are what get budgets approved and change how teams build software.
- Smaller Breach Impact: A hacker can’t steal data you never stored. This directly limits liability and sensitive data exposure.
- Lower Costs: Less data means cheaper storage, faster database queries, and reduced bandwidth.
- Simpler Security: Protecting five fields is infinitely easier than securing fifty. You shrink your attack surface.
- Cleaner Code: Systems designed with minimization are often more modular and easier to maintain, because they’re built on clear purpose.
As noted by CLEI Electric Journal
“The main privacy goal discussed in the primary papers is data minimization, but also concluded that the field remains “immature” with a clear need for privacy-aware approaches for software engineering and their validation in industrial settings” – CLEI Eletronic Journal
How Can Software Architects Build Data Minimization into System Design?
This is where philosophy meets the compiler. Good architecture makes minimization the default path.
Ephemeral Processing
Process data in memory and discard it immediately. A navigation app needs your live location to guide you, but it doesn’t need to keep your entire trip history after you arrive.
Pseudonymization and Tokenization
Replace direct identifiers in data at rest with a random token. The key linking to real data lives in a separate, fortress-like system. The main application database only holds the tokens.
Data Aggregation at Ingestion
Don’t store raw, granular data if you only need summaries. Instead of logging every millisecond timestamp of a user click, increment a counter. Store “clicks per hour,” not ten thousand individual events.
Client-Side and Zero-Knowledge Processing
Let the user’s device do the work. If the raw data never hits your server, you’ve minimized it by default. Think of how modern password managers work: the encryption key never leaves your device.
How Should Data Minimization Influence UI and Database Design?
Minimization starts long before the database INSERT statement.
Minimal Form Design
The first line of defense is the interface. Default forms to ask for the bare minimum. If you need age verification, use a simple “I am over 18” checkbox instead of a birthdate field. Every field you remove is a data point you never have to secure or delete.
Schema Design Best Practices
- Avoid Generic Blobs: JSONB or TEXT columns that dump unvetted metadata become PII dumping grounds.
- Embrace Nullability: Make non-essential fields non-existent in the schema, not just nullable. If a “middle name” column doesn’t exist, no one can accidentally fill it.
- Strict Typing: Use ENUM types or foreign keys to constrain input. This prevents garbage data from entering in the first place.
Avoiding Uncontrolled Metadata Storage
Be ruthless about what gets attached to a record. Audit third-party libraries and APIs—they often silently add tracking headers, device fingerprints, or geolocation tags you never asked for.
What Logging and Telemetry Practices Support Data Minimization?
Credits: Techstrong TV
Our logs are a chronic source of accidental data leaks. We treat them like a toxic waste stream that needs careful handling.
Log Sanitization
Implement middleware that applies data masking before it’s written. Scan for email patterns, credit card numbers, or auth tokens and replace them with [REDACTED] or a hash. This should happen in your application code, not in a downstream log aggregator.
Production Debug Controls
DEBUG and TRACE logging levels must be disabled in production. They often dump full request/response payloads. We use structured logging with explicit allow-lists for what gets included.
Privacy-Focused Telemetry Collection
We’ve moved towards models that store only what’s essential. For example, some open-source analytics platforms store exactly five fields per event: event_name, session_id, timestamp, platform, and country. They derive the country from an IP address held fleetingly in RAM, then discard the IP immediately. Session IDs themselves are kept in volatile memory and forced to expire every few hours.
Why Do Soft Deletes Often Violate Data Minimization Principles?
The standard is_deleted flag is a compliance trap. It’s data preservation, not minimization. The record, with all its PII, sits permanently in your database, just hidden from the UI.
| Approach | Benefit | Risk | Minimization Impact |
| Soft Delete | Prevents accidental loss; easy for support to restore. | Creates a hidden data archive; violates “right to erasure”; expands attack surface. | Fails. Data is retained indefinitely. |
| Hard Delete | Permanently removes data; fulfills legal deletion requests. | Irreversible; requires robust backup/restore procedures. | Succeeds. Data is actually minimized. |
The fix is to treat soft deletes as a short-term grace period, say 30 days after which an automated job permanently purges the records. The soft delete is a temporary staging area, not a final destination.
How Can Organizations Automate Data Retention and Deletion?
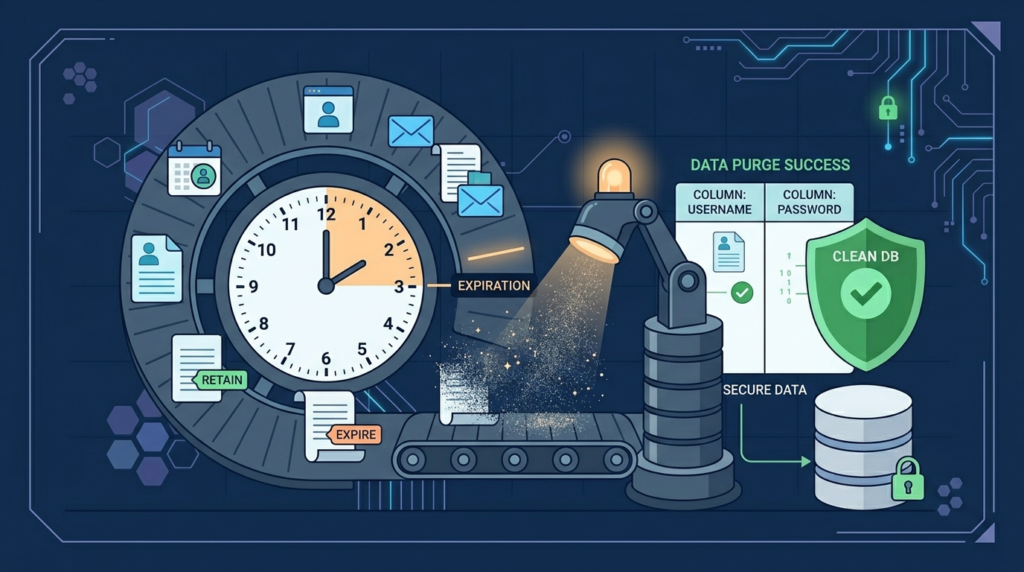
Manual processes fail. Automation is non-negotiable.
- Define TTL Policies: Every table should have a retention_period attribute. Database-level TTL or nightly cron jobs enforce it.
- Build Purge Pipelines: Deletion isn’t a one-time DELETE query. It’ s a pipeline that handles dependencies, archives for legal hold, and updates search indices. We build these as idempotent, monitored batch jobs.
- Verify Deletion: Don’t just assume it worked. Generate audit logs confirming record counts before and after purges. This is your evidence for regulators.
A common pattern: user requests deletion → record is soft-deleted (30-day grace period) → automated reaper job permanently deletes all data for that user ID → audit log is generated.
What Engineering Trade-Offs Should Teams Expect?
Minimization isn’t free. It forces hard choices.
| Area | Conflict | Our Approach |
| Analytics & AI | Models crave vast historical datasets. | We use synthetic data, differential privacy, or aggregated features. We train on the pattern, not the personal details. |
| Debugging & Support | Fixing bugs needs context. | We use opaque correlation IDs. Support gets a timeline of events linked to an ID, not the user’s personal data, and access is time-limited. |
| Operational Complexity | Purging scripts, tokenization services it’s extra work. | We frame it as technical debt reduction. Less data means faster queries, simpler backups, and cheaper infra bills. The upfront cost pays down long-term risk. |
How Can Developers Apply Data Minimization Throughout the SDLC?
Make it part of the rhythm, from kickoff to sunset.
- Planning: “What’s the minimum data this feature needs?” is a required ticket field.
- Design Review: Schema changes are scrutinized for new nullable fields or JSON blobs.
- Development: Linters flag code that logs potential PII. New service templates include sanitization middleware.
- Testing: Deletion and retention workflows are part of the integration test suite.
- Deployment & Monitoring: Retention jobs are monitored as critically as revenue pipelines.
FAQs
How do anonymization software techniques differ from standard data masking?
Anonymization software removes personal identifiers. This makes it impossible to link data to individuals. Standard data masking replaces sensitive values with realistic substitutes while preserving data structure. Organizations often use anonymization for data sharing and masking for testing environments.
When should pseudonymization software tools be used instead of masking?
Pseudonymization tools replace direct identifiers. They use substitute values. A secure link to original records is kept. Organizations use this for customer behavior analysis. It’s also used for audits and business operations. Personal identities are not exposed.
Can synthetic data generation software replace production data entirely?
Synthetic data generation software creates artificial datasets. These mimic real information’s statistical patterns. This reduces privacy risks during testing and development. However, organizations must validate synthetic datasets. They may not reflect all production scenarios or edge cases.
How does least privilege data access support masked environments?
Least privilege data access limits users. They only get information needed for their job. This reduces exposure to sensitive records. It limits the impact of unauthorized access. It strengthens data masking in development, testing, and analytics.
Why is privacy by design data minimization important for masking projects?
Privacy by design data minimization requires collecting only necessary information. This information is used and retained for a defined business purpose. This reduces the amount of sensitive data needing protection. It lowers compliance risks. It improves data masking program effectiveness.
Data Minimization Starts with One Simple Question
Data minimization is one of the simplest ways to reduce security risk without adding complexity to your development process. Every field you remove, every log you limit, and every record you delete lowers your attack surface and makes compliance easier to manage. The key is building the habit of questioning every piece of data before collecting it.
If you want hands-on guidance for applying these secure coding practices in real projects, the Secure Coding Practices Bootcamp helps developers build practical security skills through live exercises and real-world examples. Join here: Secure Coding Practices Bootcamp.
References
- https://investigadores.unison.mx/en/publications/a-systematic-mapping-study-of-privacy-by-design-in-software-engin/
- https://dlnext.acm.org/doi/fullHtml/10.1145/3531146.3533148