When untrusted data gets into protected zones without checks, attackers slip through. A trust boundary violation is when code takes outside information and uses it without questioning whether it’s safe. Imagine leaving your front door open when someone walks in, finds your wallet on the table.
A forgotten validation step, a database query built from what a user typed, or letting verified and unverified data mix together. These slip-ups add up fast. One careless function can expose your whole database. Understanding where these boundaries sit in your system matters. See real cases next and discover how to actually secure them.
Key Takeaways
- Trust boundary violations happen when untrusted data or control flows enter trusted contexts without validation.
- Common examples include unvalidated user input, mixing trusted and untrusted data, and weak isolation in multi-agent systems.
- Applying Secure Coding Practices like input validation, strict isolation, and strong authentication can drastically reduce these risks.
What Is a Trust Boundary Violation?
Trust boundaries are the invisible lines separating what your system should trust from what it shouldn’t. Effective defining and managing trust boundaries ensures these crossing points are clearly marked and guarded. When data or control crosses these lines without validation or sanitization, that’s a trust boundary violation, the system accepts something it has no business trusting.
We worked on a web application once where developers passed user input directly into SQL queries. No filters, no checks. That’s a textbook violation right there. The untrusted user data breached straight into the database layer, and SQL injection vulnerabilities opened up fast. Basic input validation would’ve stopped it cold.
The root cause of many security failures traces back to this single mistake: not questioning where data comes from before using it. Injection attacks, privilege escalation, data leaks, these problems often start here.
Common Examples of Trust Boundary Violations

User Input Without Validation
User input sits at the front lines of your security perimeter. Understanding what are trust boundaries security means recognizing that user inputs must always be treated as untrusted until validated. When we accept data from users and push it directly into system processes without sanitization, we’re inviting attacks like SQL injection or cross-site scripting (XSS).
A form field accepting usernames without filtering seems harmless until malicious scripts run on your website. We encountered a client whose customer verification system failed to validate input, and false identities slipped through. The trust boundary collapsed. Our students learn early: always sanitize and validate user inputs before the system touches them.
Mixing Trusted and Untrusted Data
Developers sometimes combine data from internal trusted sources with external untrusted data in the same structures, and that’s where boundaries blur. When we mix user-supplied information with backend data in a single database query without escaping, disaster follows. It’s like mixing clean water with contaminated water and hoping nobody notices.
Keeping trusted and untrusted data isolated, preferably in separate structures, prevents this contamination. We make sure our bootcamp students understand this separation isn’t optional, it’s foundational.
Unvalidated Data Across Modules
Data traveling between software modules can cross trust boundaries invisibly. Identifying trust boundaries application architecture helps us pinpoint exactly where data shifts trust levels between modules. A low-trust module (like a frontend API) might pass data to a high-trust module (like backend services), and if we skip validation at that handoff, serious risks emerge.
We studied a microservices setup where one service blindly accepted data from another without checking it first. Privilege escalation followed. The high-privilege service executed unauthorized commands because it trusted something it shouldn’t have. Our approach: enforce validation at every module boundary. Don’t trust upstream modules blindly, even if they seem reliable.
Insufficient Isolation in Multi-Agent Systems
Multi-agent systems involve different agents with varying privilege levels interacting together. If a low-privilege agent gets compromised and sends malicious data to a high-privilege agent, the trust boundary shatters.
Picture a bot in a financial trading system sending unauthorized commands to a compliance agent. We’ve observed how poor isolation and weak authentication between agents invites this kind of attack. Our training covers implementing strict isolation and robust access controls, these aren’t extras, they’re requirements.
Shared Resource Contamination
Multiple components sometimes share resources like databases or memory, and that’s where a less trusted component can contaminate the shared resource and indirectly compromise trusted components.
We’ve seen a compromised customer service agent corrupt shared document processing resources, affecting fraud detection systems relying on the same data. Our students learn to isolate resources and enforce access controls to prevent this kind of cascade failure.
Improper Authentication Between Components
Components occasionally fail to authenticate each other properly. This lets less trusted sources access sensitive functions or data they shouldn’t reach. A web application might allow HTTP session trust violations if session tokens aren’t validated correctly.
We emphasize that strong authentication and authorization mechanisms protect these boundaries. Your components need to know who they’re talking to, and they need to verify that knowledge every single time.
Consequences of Trust Boundary Violations
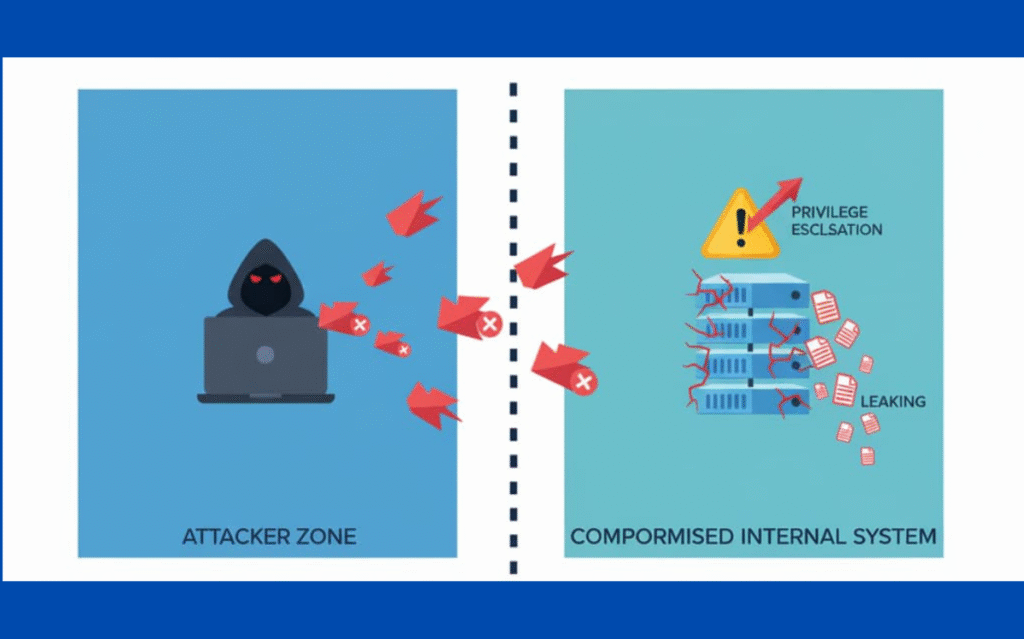
Trust boundary violations don’t sit quietly, they trigger cascading problems across systems. Injection attacks like SQL injection and cross-site scripting become possible entry points. Attackers gain unauthorized control through privilege escalation. Distributed environments suffer especially hard because trust boundaries are what hold them together, and when those fail, everything fragments.[1]
We watched a horizontal propagation attack unfold in a multi-agent environment once. One compromised agent infected the others due to weak isolation between them. The chain reaction spread faster than anyone expected, and containing it became nearly impossible.
The incident taught us that boundaries aren’t theoretical, they’re what actually keeps your system from collapsing. Beyond the immediate damage, violations breach least privilege principles, corrupt data integrity, leak confidential information, and ultimately destroy the assumptions your system depends on to function.[2]
How to Mitigate Trust Boundary Violations
Understanding where violations happen is half the battle. Fixing them requires deliberate action, and our first line of defense remains Secure Coding Practices. These practices build strong walls at trust boundaries so untrusted data stays where it belongs, outside the protected zones.
| Violation Type | Mitigation |
| User Input Without Validation | Strict input validation and sanitization |
| Mixing Trusted and Untrusted Data | Isolate data, use separate structures |
| Unvalidated Data Across Modules | Enforce validation at module boundaries |
| Insufficient Isolation (Multi-Agent) | Strong isolation and access controls |
| Shared Resource Contamination | Resource isolation and access controls |
| Improper Authentication | Strong authentication and authorization mechanisms |
Secure Coding Practices First
Our bootcamp students start here because this is where prevention actually works. We enforce input validation at every entry point where external data enters the system. Data separation matters too, trusted information and untrusted information belong in different structures, never mixed.
Authentication between components becomes non-negotiable. When developers build these practices into their code from the start, they eliminate most violations before they happen. Prevention beats cleanup every time.
Design With Trust Zones in Mind
Credits: Practical DevSecOps
Software architecture needs to explicitly define trust zones. That means strict interfaces controlling how data moves between zones. When we design systems without clear trust zones, data from different trust levels bleeds together inside the same structures, and that’s where attackers find their opening.
We guide our students to think about architecture as the skeleton holding security together. Without it, individual secure coding practices only go so far.
Continuous Monitoring and Incident Response
Even well-designed systems need watching. We monitor communication crossing trust boundaries to catch anomalies early, unusual data patterns, unexpected connections, privilege escalations that don’t match normal behavior.
Quick incident response matters here. When a breach gets detected, containing it fast prevents that horizontal propagation we mentioned earlier. The faster a team responds, the fewer systems get compromised before the attack stops spreading.
FAQ
What are common trust boundary violation examples in modern systems?
Trust boundary violation examples often appear when untrusted data enters a trusted zone without checks. You’ll see mixing trusted and untrusted data, unsafe data handling, or untrusted source acceptance in web application trust boundary paths. These trust boundary security issues create openings for data trust boundary breach, validation failure examples, or trust boundary coding error. Even simple trust boundary error cases can trigger wider trust boundary exploit examples.
How do unvalidated input vulnerability issues lead to bigger trust boundary security risks?
An unvalidated input vulnerability can open the door to SQL injection trust boundary problems, cross-site scripting trust boundary issues, and insecure data flow crossing between data trust zones. When lack of input validation lets untrusted data in, you get trust boundary isolation failure or unsafe data handling. These software vulnerability trust boundary flaws expand the trust boundary attack surface and increase trust boundary security risk factors.
How do multi-agent trust boundary violations spread across connected systems?
In multi-agent trust boundary violation scenarios, insufficient agent isolation and weak inter-agent authentication create openings for cross-agent state contamination or shared resource contamination. One compromised customer service agent or risk assessment manipulation event can trigger horizontal propagation attack or vertical escalation attack patterns. This often becomes a hub-and-spoke attack pattern, creating chain reaction compromises and multi-agent system trust failure across shared resource security flaw zones.
How can financial services face trust boundary compromise impact?
Financial services trust breach events may start with document processing compromise, customer verification false identity, or trading compliance agent breach. Attackers might abuse cross-agent privilege inheritance or impersonation in trust boundary paths. These trust boundary security breach issues create trust boundary compromise impact that spreads through authorization boundary violation or trusted context misuse, especially when trust model design flaws and trust boundary enforcement weaknesses go unnoticed.
What clues point to a trust boundary management failure in software architecture?
A trust boundary management failure may appear as security domain violation, API trust boundary violation, or authorization boundary violation caused by trust boundary in software architecture errors. Developers may miss trust boundary integrity failure or insufficient monitoring trust breach signals. Cloud trust boundary violation and trust boundary in microservices often show insecure data flow crossing, trust boundary defect detection gaps, or session management flaws that enable data leakage.
Wrapping Up Trust Boundary Violation Examples
Trust boundary violations, SQL injections from unvalidated input, privilege escalations in multi-agent systems, expose how fragile software becomes without proper safeguards. Our experience shows this demands Secure Coding Practices, clear architectural boundaries, and vigilant monitoring.
Start by auditing how your system handles data crossing trust zones. Are inputs validated? Are trusted and untrusted data separated? Do agents authenticate? These questions close gaps attackers exploit. Reducing the attack surface requires smart design, disciplined coding, and constant attention.
If you want to strengthen your team’s ability to build safer systems from the ground up, consider joining the Secure Coding Practices Bootcamp, a hands-on, developer-focused training program designed to teach practical secure coding skills. Learn more or enroll here: Join the Bootcamp.
References
- https://www.itpro.com/security/74-percent-of-companies-admit-insecure-code-caused-a-security-breach
- https://www.bleepingcomputer.com/news/security/privilege-elevation-exploits-used-in-over-50-percent-of-insider-attacks/
Related Articles
