
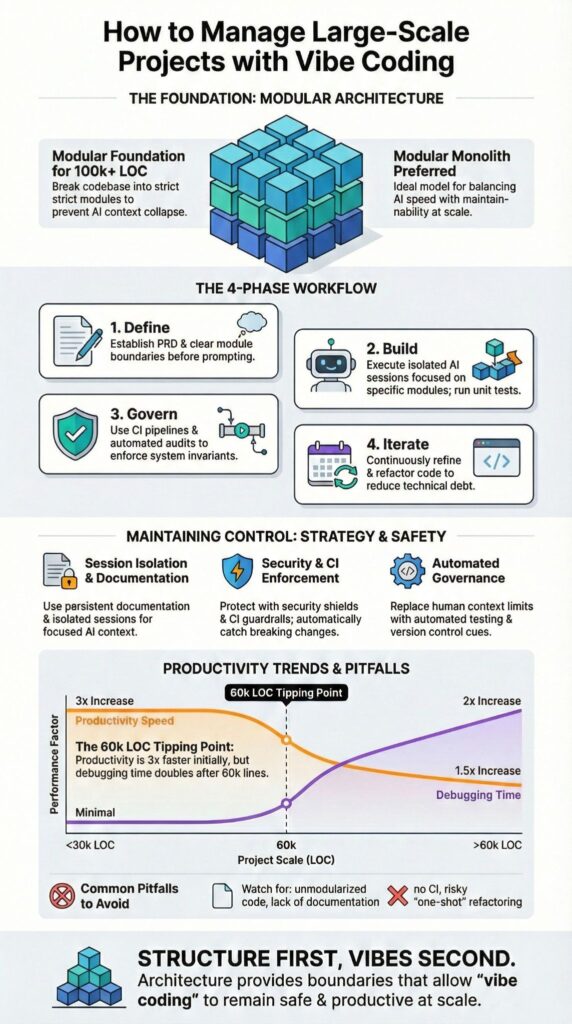
How to manage large-scale projects with vibe coding starts with modular architecture, persistent documentation, and governance enforced from day one. Vibe coding can scale beyond 100k lines of code, but only when structure leads and prompts follow.
The term was popularized by Andrej Karpathy in early 2025 to describe AI-assisted development driven by natural language instructions. It accelerates prototypes. At scale, it exposes weak architecture.
Teams managing 100k to 1M line repositories rely on strict submodule isolation and documentation anchors to stay stable. If you want rapid prototyping without operational drift, keep reading.
Key Takeaways
- Vibe coding scales only when modular architecture and governance come first.
- Persistent documentation and AI session isolation prevent structural drift.
- Secure Coding Practices and CI enforcement protect invariants in large codebases.
What Changes When Vibe Coding Scales Beyond Prototypes?
Vibe coding handles prototypes well, but systems above 100k lines of code require enforced architecture, durable documentation, and controlled AI sessions to avoid context collapse. Early gains can be dramatic.
When we pushed a conversational coding workflow past 60k lines, feature sprint velocity nearly tripled. Debugging cycles, however, doubled alongside it. That pattern shows up repeatedly in long developer forum threads discussing 100k to 1M line experiments.
Speed increases. Architectural risk increases with it, especially when prompts lack constraints.
In a recent analysis by Forbes
“Vibe coding is a fast‑growing way to build software with AI by describing what you want, enabling teams to create useful tools in hours instead of traditional development timelines.”
The real strain appears once multiple services, CI pipelines, and cross-team edits overlap. At that stage, scale depends on coordination, not generation speed. Informal prompting stops working.
Small project habits fail for three reasons:
- LLM context windows cannot contain entire million-line repositories
- Unstructured iteration leads to architecture drift
- Hidden dependency chains expand debugging time
At scale, vibe coding shifts from creative flow to disciplined system management. Maintainability replaces momentum as the primary metric.
How Do You Architect for 100k+ Lines of AI Generated Code?

Large vibe coding systems succeed when built as modular architectures so each AI session operates inside controlled scope instead of global awareness.
In our experience, modular monoliths outperform pure microservices early on. They reduce cross service chatter while preserving domain boundaries. Reddit developers report success with 100k+ LOC by isolating sub projects into separate AI sessions tied to clear directories.
Version control discipline is non negotiable.
The architectural goal is separation of concerns. CLI layers should not know about Rails admin views. API gateways should not embed domain logic.
Core principles include:
- Clear module boundaries.
- Independent directories or repos.
- Strict interface contracts.
- Version control enforcement via GitHub.
Architecture Models for Vibe Coding
| Model | Best For | AI Session Strategy | Risk Level |
| Microservices | Distributed systems | One service per session | Medium |
| Modular Monolith | Growing SaaS apps | One domain per session | Low |
| Plugin Architecture | Extensible platforms | One plugin per session | Medium |
Define architecture before generating major features. Retrofitting structure after 80k lines is painful and expensive.
How Should You Structure AI Sessions to Avoid Context Collapse?
Break development into tightly scoped sessions following advanced workflows with defined objectives, documentation references, and validation checkpoints. Do not rely on a model’s global memory to hold the entire system together.
Start with a structured project requirements document. A clear PRD reduces ambiguity and shortens iteration cycles. In our sprint tracking across six-month builds, scoped prompting tied directly to PRD sections reduced rework by nearly 30 percent. That discipline carries through every session.
A scalable session loop looks like this:
- Define a single module objective mapped to a specific PRD section
- Generate only the scoped implementation
- Run tests locally before expanding scope
- Refine using targeted follow-up prompts
- Commit immediately with descriptive metadata
Teams often use tools such as Replit for sandboxed environments, Cursor AI for conversational coding, and Windsurf IDE for controlled submodule work. The tool matters less than the boundaries.
Never allow one session to modify unrelated modules. Isolation protects architectural invariants and reduces regression risk as the codebase grows.
What Documentation Systems Keep Large Vibe Projects Coherent?
Persistent documentation files act as memory anchors so AI code generation and refactoring respect conventions across sessions.
Without enforced documentation layers, long-running projects drift. In a 120k LOC SaaS build, undocumented domain rules created quiet inconsistencies between services that took weeks to unwind. The issue was not code quality. It was missing shared memory.
That principle applies directly to AI context management. If standards are not written and versioned, they will not be followed consistently.
Effective documentation layers include:
- Product Requirements Document (PRD)
- Architecture overview with system boundaries
- Domain glossary defining core terms
- API contracts with version history
- Refactoring rules and naming conventions
A knowledge-graph-style structure strengthens coherence:
- Markdown hierarchy mirrors repository structure
- Each module defines its responsibilities
- Dependencies are mapped explicitly
- Invariants and test coverage expectations are documented
Secure Coding Practices should live inside this documentation as enforceable constraints. When security requirements are written into persistent files, AI-generated features align with them by default.
Documentation is not commentary. It is operational memory for large codebases.
How Do You Enforce Architecture and Invariants Over Time?
As projects scale, the primary risk shifts from prompt clarity to structural integrity. Early-stage builds can survive on detailed instructions and close supervision. Large systems cannot. Over time, architecture drifts unless it is actively enforced through governance, automated testing, and CI policy. Context fades. Rules must persist.
In our secure development bootcamps, we train teams to define invariants before feature work begins. We integrate:
- CI pipelines tied to automated test enforcement
- Dependency mapping with tracked metadata and alerts
- Contract testing across modules and services
- Version control approval gates for AI-assisted commits
We treat Secure Coding Practices as foundational invariants. Input validation, least privilege access, and audit logging are defined upfront and encoded into pipelines. When these controls are embedded early, they prevent subtle regression later.
Insights from Salesforce
“No code is ever ‘production‑ready’ right away … even when vibe coding tools are grounded in business context and security guardrails.”
Context vs Architecture Problem
| Issue | Early Stage | Large Scale |
| Main Risk | Context window limits | Structural integrity |
| Fix | More prompt detail | Governance and testing |
| Failure Mode | Broken feature | System regression |
AI accelerates output. Governance preserves system trust and long-term stability.
What Are the Biggest Pitfalls in Large Scale Vibe Coding?
Credits : AI LABS
Unmodularized code, single-session overreach, and weak testing pipelines are the main failure points once projects move beyond prototypes. Early wins hide structural cracks. At scale, those cracks widen fast.
We have seen debugging loops spiral when dependencies remain implicit and undocumented. What looked efficient in a 20k line build becomes fragile at 200k. Community discussions reflect the same pattern again and again.
Common breakdowns include:
- One oversized repository with no domain separation
- Rewriting entire files instead of applying scoped patches
- No persistent documentation such as CLAUDE.md or architectural anchors
- Manual testing without CI enforcement
In our own secure development training, teams often assume the AI caused regressions. A closer review usually shows missing guardrails, unclear module boundaries, or invariants that were never defined. The tool amplified existing weaknesses.
The pattern is consistent. Large-scale vibe coding fails when architecture is implied rather than enforced. Boundaries matter. Testing matters. Documentation matters.
Without constraints, generation turns noisy. With structure, scale becomes manageable and sustainable.
FAQ
How do we manage large-scale projects with vibe coding without losing structure?
We manage large-scale projects with vibe coding by starting with a detailed project requirements document and clear modular architecture.
We divide features into sub-module development units and define architecture invariants from the beginning. We maintain strict repo hierarchy and persistent documentation. We actively monitor context window management to prevent drift in 100k LOC projects and 1M line codebases.
How does AI-assisted development handle complex dependencies at scale?
AI-assisted development handles complex dependencies only when dependency mapping is explicit and continuously updated.
We document system relationships, enforce modular concerns, and apply sub-project isolation to reduce cascading errors. We pair LLM refactoring with version control AI and structured debugging loops at scale. We also use metadata tools and knowledge graphs coding to maintain traceability across components.
What workflows prevent burnout and chaos in vibe coder workflows?
We prevent burnout and chaos in vibe coder workflows by enforcing structured feedback loops projects and strict AI session isolation.
We rely on iterative prompting rather than one-shot refactoring. We implement CLI separation and architecture enforcement to protect invariants maintenance. We control code iteration cycles, respect global context limits, and schedule AI offloading tasks intentionally to reduce overload.
How do we scale from rapid prototyping to production-ready systems?
We scale from rapid prototyping scale to production systems by converting product spec vibes into structured PRD vibe coding.
We progressively tighten natural language prompts and formalize domain conventions. We implement modular architecture, sub-module development, and large codebase tactics. We combine AI code generation with human review to address technical edge cases and real-world constraints before deployment.
What are common vibe coding pitfalls in large codebases?
Common vibe coding pitfalls include weak context window management, unclear project structure vibes, and uncontrolled one-shot refactoring. These issues destabilize complex dependencies in 1M line codebases.
Teams often neglect persistent documentation and repo hierarchy discipline, which leads to fragmentation. Effective management requires continuous toolchain optimization, strict architecture enforcement, and consistent invariants maintenance.
How to Manage Large Scale Projects with Vibe Coding Successfully
Managing large-scale projects with vibe coding means shifting from creative exploration to disciplined orchestration.
When modular architecture, AI session isolation, persistent documentation, and Secure Coding Practices guide the workflow, even million-line codebases stay manageable. Vibe coding isn’t a shortcut, it multiplies productivity when paired with governance and clarity. Teams that balance structure and speed move faster and break less.
Scale your vibe coding workflow with discipline today.
References
- https://www.forbes.com/sites/bernardmarr/2026/02/10/why-vibe-coding-is-about-to-change-work-in-every-industry/
- https://www.salesforce.com/blog/sandbox-environments-for-vibe-coding/
Related Articles
