We’ve seen this pattern over and over in our bootcamps: the API works, data moves cleanly, and everyone relaxes too early. Then comes the real question, where does control actually stop? That invisible cutoff is the API trust boundary, the line between trusted behavior and everything else. In many real-world cases, breaches stem from unclear ownership of trust boundaries.
In our secure development training, we treat every boundary crossing like a security event, logged, checked, and verified. If you’re serious about keeping attackers out, keep reading and learn how to harden those boundaries on purpose, not by accident.
Key Takeaways
- Define Your Zones: Clearly map which parts of your system are trusted and which are not.
- Validate all inputs based on strict, predefined schemas: Treat all incoming data as untrusted until proven otherwise.
- Monitor the Crossings: Log and analyze every request that passes a trust boundary.
The Invisible Line That Protects Everything
An API trust boundary isn’t a physical thing. You can’t touch it. It’s a conceptual line, a security checkpoint where data or control passes from one domain of trust to another. Think of it as the passport control between countries.
Inside your secure internal network, you might have a high level of trust. The moment a request comes from the public internet, it crosses a boundary into a zone of lower trust. The management of this boundary is what separates a secure API from a vulnerable one. It’s where you decide who gets in and what they’re allowed to do.
Neglecting this boundary is equivalent to leaving a critical checkpoint unguarded. Some companies experience repeated API attacks, 41% of those breached had five or more API-related incidents over two years. The risks are real and severe. Data breaches often start at a poorly defended trust boundary. (1)
The goal isn’t to build an impenetrable wall, but to create a series of intelligent, monitored gates. Every crossing is an opportunity to verify, to sanitize, to log. It’s a continuous process, not a one-time setup. You’re building a living defense.
These moments often echo subtle boundary violations that slip past teams when trust assumptions are too loose.
Internal APIs are often treated as safe, which can be dangerous if controls aren’t applied consistently. A zero trust model suggests that no entity should be trusted by default, even if it’s inside the network. This means applying boundary controls between internal microservices as well.
The principle is the same: authenticate, authorize, validate. It’s about applying consistent security logic wherever a trust level changes. This layered approach significantly reduces your overall attack surface.
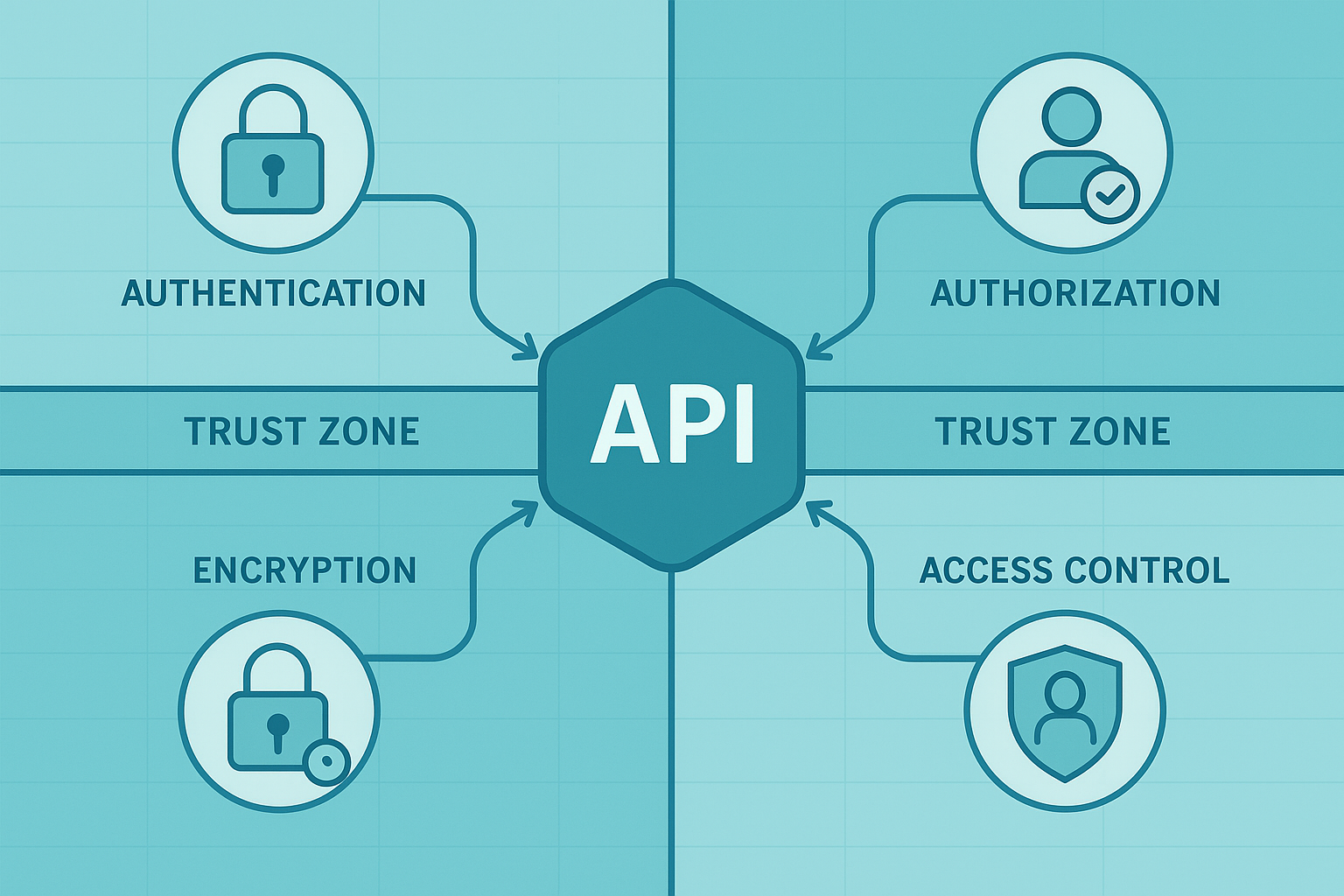
Core Elements to Fortify Your Boundary
To build an effective defense, you need to focus on a few critical areas.
- Robust Authentication: Verify the identity of every caller using standards like OAuth or API keys.
- Strict Authorization: Enforce what an authenticated identity is permitted to do using role-based or attribute-based access control.
- Rigorous Input Validation: Scrutinize every piece of data entering your trusted zone for malicious content.
- End-to-End Encryption: Use TLS to protect data confidentiality and integrity as it travels across networks.
Mapping Your Territory: Identify Trust Zones
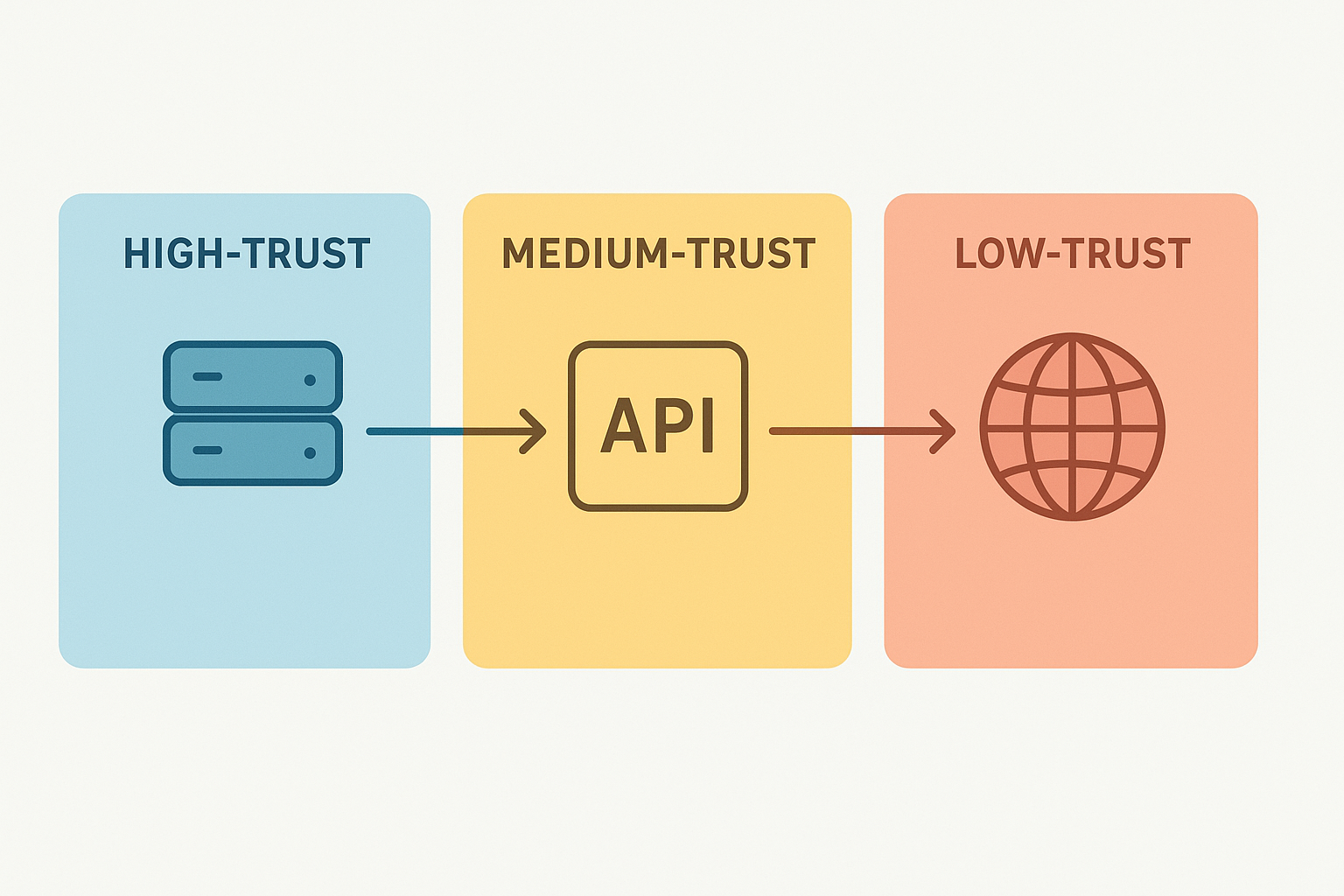
You can’t protect what you don’t understand. The first step is to create a map of your API ecosystem. Identify all the components. Where do your users come from? What third-party services do you integrate with? Which databases hold sensitive information? Draw the lines. Your internal server cluster might be a high-trust zone.
The public internet is a low-trust zone. A partner’s API might be a medium-trust zone. This mapping exercise is foundational. It forces you to think about data flow and points of exposure.
It forces you to think about how data flow diagrams can reveal exposure points in ways that aren’t always obvious.
This clarity is essential for applying the right security controls. You wouldn’t use the same lock on a garden shed as you would on a bank vault. Similarly, the security at the boundary between your front-end and a public CDN might differ from the boundary between your payment service and its database.
The principle of least privilege should guide you. A component should only have the access it absolutely needs to function. By clearly defining these zones, you make informed decisions about where to invest your security efforts.
We’ve worked on systems where this mapping revealed unexpected trust relationships. A legacy service talking directly to a new cloud component without any mediation. An admin panel accidentally exposed to the wider network.
These are the gaps that attackers exploit. A simple diagram can be incredibly revealing. It doesn’t need to be fancy. Just boxes and lines that show where trust levels change. This visual model becomes your security blueprint.
The Guardians: Authentication and Authorization
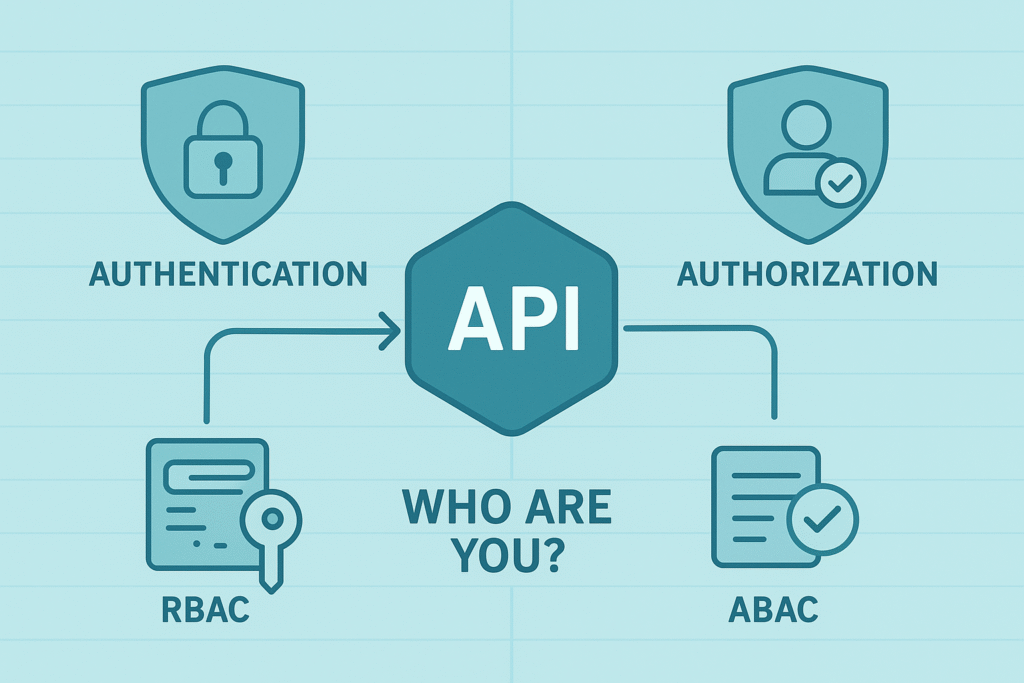
This is the classic one-two punch of access control. Authentication answers the question, “Who are you?” Authorization follows up with, “What are you allowed to do?” At every trust boundary, these questions must be asked and answered definitively.
For API calls, this often means using API keys for service-to-service authentication or OAuth 2.0 for user-delegated access. The key is to use modern, standard protocols. Rolling your own auth system is a recipe for vulnerabilities.
Authorization is where fine-grained control happens. Role-based access control (RBAC) is common, defining permissions based on a user’s role. Attribute-based access control (ABAC) can be more dynamic, considering multiple attributes like user department, time of day, or resource sensitivity.
The goal is to enforce the principle of least privilege. A user, or a service, should only have the minimum permissions necessary to perform its function. This limits the damage if credentials are compromised. What happens next depends heavily on how you’re defining trust boundaries in your system.
We implement these checks at the API gateway, which acts as a natural enforcement point for external boundaries. But don’t stop there. Internal service calls should also carry identity context. This allows for consistent authorization checks deep within your architecture.
A token obtained at the edge can be passed along, proving that the initial request was vetted. This creates a chain of trust that is auditable and secure. It turns your entire system into a coordinated defense.
Never Trust, Always Verify: Input Validation
Credits: Info Tube
This might be the most important rule in secure coding practices. You must treat all input that crosses a trust boundary as potentially malicious until it has been rigorously validated. This includes data from users, other services, even internal systems if they consume external data. Validation isn’t just checking if a field is an integer. It’s about ensuring the data conforms to strict expectations for type, length, format, and range.
Sanitization is the next step. It involves neutralizing any potentially dangerous characters or patterns. This is your primary defense against injection attacks, like SQL injection or cross-site scripting (XSS). For example, if you expect a US zip code, your validation should reject anything that isn’t five digits, or five digits followed by a hyphen and four digits. Anything else is discarded or returned with an error. This strictness prevents malformed data from causing unpredictable behavior downstream.
We advocate for a centralized validation library or framework. This ensures consistency across all your APIs. Every endpoint should have a clearly defined schema for its inputs. Tools like JSON Schema can help automate this. The validation should happen as early as possible, ideally at the very edge where the data enters your system.
Don’t let invalid data travel deep into your application logic. Catch it at the gate. This practice alone can eliminate a huge class of common vulnerabilities.
Essential Validation Checks
- Data Type: Ensure numbers are numbers, strings are strings.
- Length and Size: Enforce minimum and maximum character counts or file sizes.
- Allowed Characters: Whitelist acceptable characters, rejecting all others.
- Business Logic: Check that values make sense in the context of your application.
Securing the Journey: Encryption in Transit
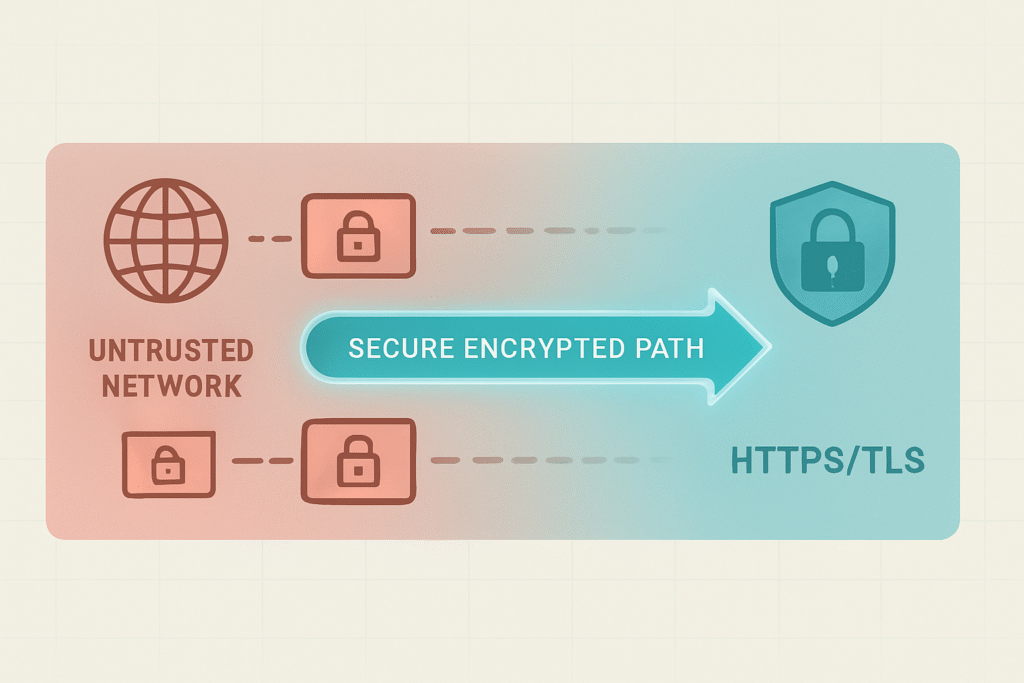
When data moves across a network, especially an untrusted one like the internet, it’s vulnerable to interception and manipulation. Encryption is the technology that scrambles this data, making it unreadable to anyone without the key.
Using HTTPS, which relies on TLS (Transport Layer Security), is non-negotiable for any API exposed to the outside world. It provides two critical guarantees: data confidentiality and data integrity.
Confidentiality means that no one eavesdropping on the connection can understand the data. Integrity means that the data cannot be altered in transit without detection. Enforcing HTTPS should be a default policy for all your external endpoints.
Redirect all HTTP traffic to HTTPS. Use strong cipher suites and keep your TLS libraries up to date. This protects your users’ data and your API’s payloads from man-in-the-middle attacks. It’s a basic hygiene practice that forms a fundamental part of the trust boundary.
But what about internal traffic? Within a data center, you might think it’s safe. In a Zero Trust model, encrypting internal traffic is strongly recommended, especially in environments with lateral movement risks. It protects against insider threats and lateral movement if a single node is compromised.
Service mesh technologies often provide this “automatic mutual TLS” for internal service-to-service communication. While the risk profile is different, the principle remains: encrypt data as it crosses any trust boundary, even internal ones. It’s a simple layer of defense that pays dividends.
The Watchtower: Monitoring and Logging
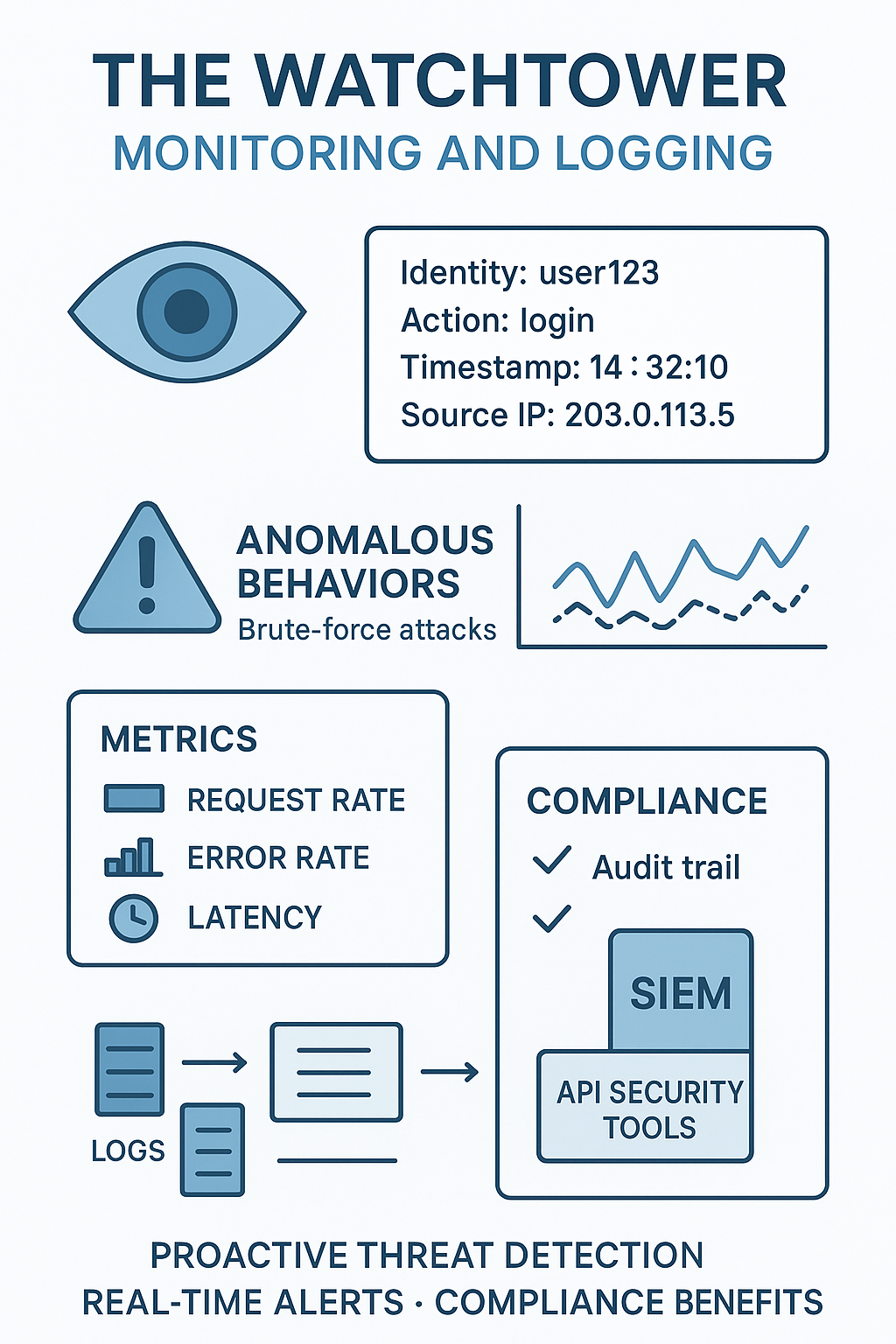
Security isn’t just about preventing attacks. It’s also about detecting them. If you don’t know what’s happening at your boundaries, you’re flying blind. Comprehensive monitoring and logging are your eyes and ears.
You need to track every request that crosses a significant trust boundary. Log essential details: who made the request (identity), what they requested (action), when it happened (timestamp), and from where (source IP).
This log data is invaluable for forensic analysis after a security incident. But its real power is in real-time detection. By feeding these logs into a security information and event management (SIEM) system or a dedicated API security tool, you can set up alerts for anomalous behavior.
A sudden spike in requests from a single IP, a series of failed authentication attempts, or access patterns that deviate from the norm. These could be signs of a brute-force attack, a credential stuffing attempt, or a compromised key.
We recommend defining a set of key metrics for your API boundaries. Things like request rate, error rate, and latency. A dramatic change in any of these can be a signal. The goal is to move from reactive security to proactive threat detection. By watching the traffic, you can often spot an attack in its early stages and mitigate it before significant damage is done.
In the Asia-Pacific region, API incidents cost enterprises on average US$ 580,000 per incident. Logging is also crucial for compliance, providing an audit trail that proves you are managing access correctly. (2) It turns your API from a black box into a transparent, accountable system.
FAQ
What is a trust boundary in API security?
A trust boundary is the line between safe and unsafe areas in your system. When an API endpoint gets a request from outside, it must treat that crossing like a risk. Using access control, authentication, API keys, TLS, and input validation helps keep data confidentiality and data integrity safe when someone steps over that trust boundary.
How do API trust zones help reduce API vulnerabilities?
API trust zones group parts of your system by risk. Each zone uses access control, least privilege rules, and role-based access control to limit who gets in. API gateway rules, API traffic filtering, encryption in transit, and secure protocols like HTTPS help block injection attacks and data breaches. This makes your overall security posture far stronger.
Why do authentication and authorization matter when crossing a trust boundary?
When a call moves across a trust boundary, the API must know who the user is and what they can do. That is why authentication, OAuth, OpenID Connect, and security tokens are important. Authorization checks and attribute-based access control stop unsafe access. Together, they keep API identity management, API integrity, and API confidentiality under control.
How can I protect APIs from malicious payloads and injection attacks?
Good protection starts with input validation and data sanitization. They block malicious payload detection problems early. An API firewall, rate limiting, API monitoring, logging, and API threat detection add more layers. Secure API design, network segmentation, session management, and zero trust model ideas reduce the API attack surface and keep API protection strong.
What helps maintain API security across the full API lifecycle?
You can use API management, API policies, and API security best practices at each step. API security testing, API audit checks, and API access logs help you watch for problems. Security boundary enforcement, service mesh security, workload security, cloud API security, and API orchestration security also support secure data exchange and steady API risk mitigation.
Conclusion
API trust boundary management is not a product you buy. It’s a discipline you build. It starts with a mindset, a healthy paranoia that assumes nothing and verifies everything. By defining your zones, enforcing strict access controls, validating every input, encrypting traffic, and continuously monitoring activity, you construct a resilient architecture. Your API becomes a fortified gateway, not an open door. This ongoing practice is what separates a robust, reliable service from a security liability.
If you want to sharpen these skills even further, the Secure Coding Practices Bootcamp trains developers through hands-on, real-world sessions, no fluff, no jargon, just practical techniques you can apply immediately.
Covering essentials like the OWASP Top 10, input validation, secure authentication, encryption, and safe dependency usage, the 2-day course includes live instruction, labs, replays, cheatsheets, and certification. Ideal for individuals or teams, with custom corporate options and volume discounts, it equips you to ship safer code from day one.
Now, go map your boundaries, your first line of defense is waiting to be drawn. Join the Secure Coding Practices Bootcamp
References
- https://www.businesswire.com/news/home/20241030645718/en/Traceable-Releases-2025-State-of-API-Security-Report-API-Breaches-Persist-as-Fraud-Bot-Attacks-and-Generative-AI-Increase-Risks
- https://www.akamai.com/newsroom/press-release/2025-api-security-impact-study
Related Articles
