Data masking swaps real, sensitive information for fake but functional data. It lets teams work with information for testing or analysis without the security risk. The goal is to protect things like personal details and financial records, not to make data useless.
You can learn more in our common data masking techniques guide. It’s a key part of Secure Coding Practices and overall data security. Keep reading to see how it works.
Quick Security Insights
Effective data masking balances privacy, compliance, and data usability while reducing exposure risks in development, testing, and analytics environments.
- Masking vs. Encryption: Masking is irreversible; encryption is reversible.
- Static vs. Dynamic: Static creates a safe copy; dynamic hides data on demand.
- Key Trade-off: More privacy often means less usability.
- Referential Integrity: Related data must stay consistent after masking.
- Compliance: GDPR requires proper data anonymization and pseudonymization.
What Are Static and Dynamic Data Masking?
Static masking creates a permanent, sanitized copy of your data. Dynamic masking hides sensitive values in real-time, leaving the original database untouched.
We find this first choice is crucial in our training. Do you change the data, or just how it’s seen?
| Feature | Static Data Masking (SDM) | Dynamic Data Masking (DDM) |
| Data Location | A separate, masked copy | The original, live database |
| Persistence | Permanent transformation | Temporary, view-based |
| Performance Impact | One-time cost, lower runtime overhead | Adds overhead to every query |
| Best Use Cases | Non-production environments (dev, test, QA) | Production support, customer service portals |
In our labs, we use static masking. Students get a safe, realistic copy of a dataset for development work.
Dynamic masking applies rules on-the-fly. A user query might return a masked phone number, while the backend system sees the real one. The trade-off is potential performance lag from the extra processing. Keep reading to decide which method you need.
What Is Substitution Masking and When Should You Use It?
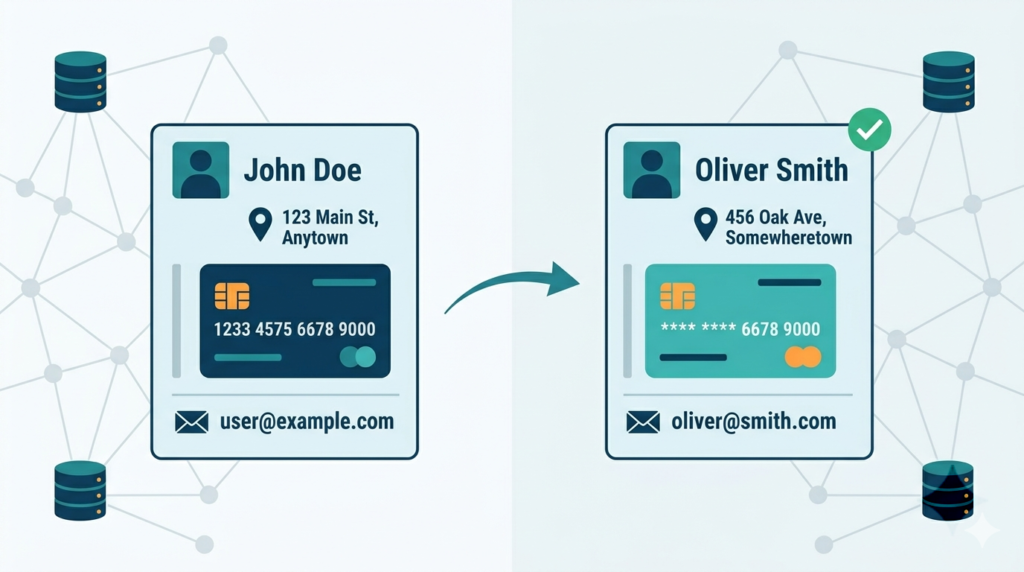
It replaces sensitive values with believable, realistic alternatives. The format and usability are preserved, making it ideal for testing.
We find it’s the most intuitive technique. You swap real data for convincing fakes. The name “John Smith” becomes “Robert Chen.” The email john.smith@company.com transforms into robert.chen@example.org.
A lookup table or rule set handles the mapping. For consistency, the same original value should always map to the same substitute across your entire dataset.
Our bootcamp uses this for names, emails, and addresses any field where you need realistic data for testing forms or reports. The result is a functional dataset that limits sensitive data exposure.
The downside is maintaining those tables. A bad substitute, like an invalid email format, will break your application. We teach that masked data must pass the same validation rules as real data, linking it directly to Secure Coding Practices. Keep reading for more.
How Does Data Shuffling Preserve Analytics Accuracy?
It rearranges values within a column, breaking the link to individual records while keeping the overall statistics the same.
Instead of inventing data, you randomize the order of existing values. Take a list of employee salaries. Shuffling them means Alice’s $50,000 might now appear next to Bob’s name, and Bob’s $120,000 next to Carol’s. The actual numbers don’t change.
This is a column-level operation. The total sum, the average, and the distribution all stay accurate. We find it’s best for numeric or categorical data used in reports. Testing a payroll dashboard with shuffled data gives you correct totals without revealing anyone’s actual salary.
As noted by Microdata Publication
“Shuffled data has a potential risk of attribute disclosure. Furthermore, data shuffling requires a ranking of the whole dataset, which can be computationally costly for large datasets with millions of records.” – Microdata Publication
But it has limits. For very small datasets, like five employees, you could still deduce who earns the most. It also completely destroys accuracy at the individual level, which is the point. Keep reading for more.
When Is Variance-Based Masking the Right Choice?
Credits: Tonic AI
Variance masking modifies dates or numeric values within controlled ranges to protect identities while preserving trends and analytical usefulness.
This technique adds “controlled noise.” You alter a value by a random amount within a defined limit.
- Date Variance: A real date of birth 1985-05-12 could be shifted by a random number of days between -10 and +10, resulting in 1985-05-05. The individual’s true birthday is hidden, but the person’s age group and any month-based trends are retained.
- Numeric Variance: A transaction amount of $124.67 could be varied by +/- 5%, becoming $130.90. The overall financial profile and testing of rounding logic remain valid.
- Best for: Protecting direct identifiers like birthdates in health records (crucial for HIPAA compliance) or obfuscating precise financial figures while maintaining ledger integrity. A common variance for dates is ±10 days.
- Consideration: You lose precise individual accuracy. It’s perfect for analytics, but problematic if you’re testing a feature that sends a “Happy Birthday!” email on the exact date.
How Do Encryption and Tokenization Differ?
Both protect sensitive data, but they work differently. Encryption scrambles data into ciphertext using data encryption. Tokenization replaces a real value with a random token, storing the original in a separate, secure vault.
We teach the core contrasts like this:
| Factor | Encryption | Tokenization |
| Reversible | Yes, with the key. | Yes, by mapping the token back in the vault. |
| Algorithm | Mathematical (AES, RSA). | Non-mathematical; uses a lookup vault. |
| Format Preservation | Usually no. Output is binary/hex. | Often yes. Can preserve format (e.g., a 16-digit token for a card). |
| Scope | Protects data anywhere. | Protects specific, vaulted data elements. |
| Primary Use | Securing data at rest/in transit. | Securing payment data (PCI DSS), identifiers. |
- Encryption turns a number like “4421 1234 5678 9012” into unreadable text like “aG93ZHkuY29t”. You need the key to reverse it. It’s good for securing files, but the output is useless for testing.
- Tokenization gives you a token like “tok_1a2b3c4d”. The real data stays in a vault. This is the standard for payments, as it protects data without breaking an app’s expected format. Keep reading for more.
What Is Character Masking (Redaction)?
Character masking hides selected portions of sensitive values while leaving limited information visible for verification and customer service workflows.
This is the “black marker” approach. You display only part of the data.
- Common Patterns:
- Social Security Number (SSN): XXX-XX-1234
- Credit Card: **** **** **** 4321
- Email: j******@domain.com
- Best for: User-facing applications. A call center agent can verify the last 4 digits of an SSN to authenticate a caller without seeing the full number. It’s simple and highly effective for its narrow use case.
- The Drawback: It destroys the data’s utility for anything other than visual confirmation. You can’t run a test that requires a full, valid email address on a redacted one.
Is Nulling Out Data Ever a Good Option?

Nulling removes sensitive information entirely and works best when the affected fields are unnecessary for testing or analysis.
The simplest technique: replace the value with NULL, an empty string, or a generic placeholder like [REDACTED].
- The benefit: It’s completely secure and incredibly fast to implement. There’s nothing to reverse-engineer.
- The risk: It will absolutely break your application if that field is required. If your database schema has a NOT NULL constraint on the email column and you null it out, your inserts will fail. Systems like Oracle Database will throw immediate errors.
- Ideal scenario: Removing optional data fields that are collected but not used by downstream processes. For example, nulling out a “Middle Name” field that isn’t used in any application logic, reports, or validation rules.
Why Does Masked Data Still Break Production Despite Compliance Efforts?
Poor masking implementations can break validation rules, application logic, and downstream workflows even when compliance requirements appear satisfied.
Checking a compliance box doesn’t mean your systems will work. We’ve seen teams pass audits but watch their staging environments crash because masked data didn’t meet real-world requirements.
- Format Failures: A substitution rule generates an email name.example.com (missing the @). Every email validation function in your app fails.
- Constraint Violations: Masking is supposed to generate unique fake names, but a flaw causes duplicates on a column with a unique database constraint. Inserts start failing.
- Application Logic Breaks: A feature calculates a discount based on a customer’s sign-up anniversary. Date variance masking changes the date, so the discount never triggers.
- Performance Meltdowns: On forums like Reddit, DBAs tell horror stories of dynamic masking policies that cause full table scans, leading to 100% CPU utilization and timeouts. Your compliance tool just caused a production outage.
How Can You Preserve Referential Integrity Across Systems?
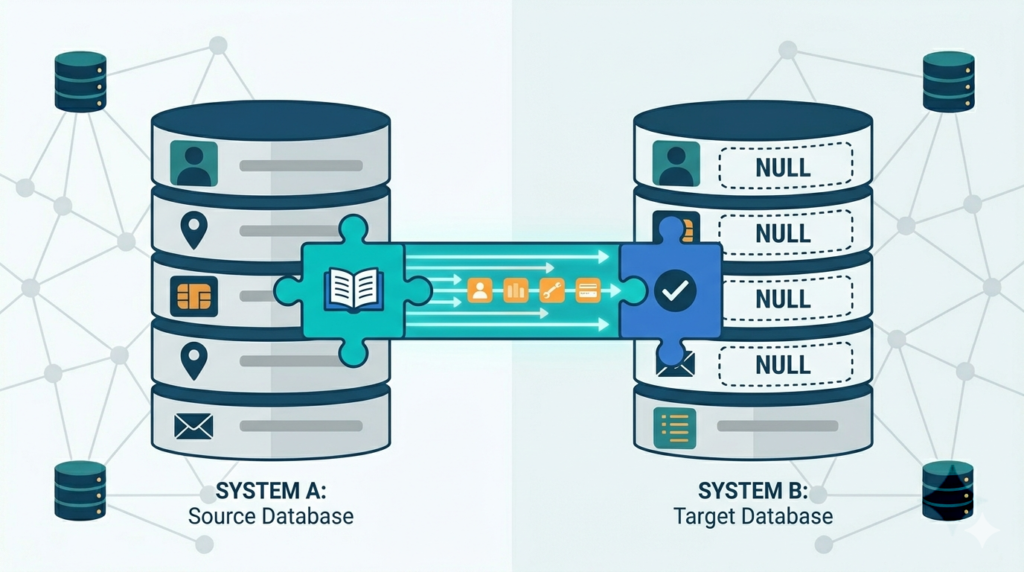
Consistent masking across databases ensures linked records remain connected without exposing sensitive information.
This is one of the hardest problems. Your customer data lives in a PostgreSQL app database, a Snowflake data warehouse, and a MongoDB document store. If you mask the Customer ID differently in each place, you can’t join data across systems for testing or analytics.
- Deterministic Masking: Use a seeded algorithm. The input “CustomerID: 1001” always produces the same masked output “XyZ-789” across every platform, guaranteeing the link is maintained.
- Token Vault: The most robust method. Generate a token for “CustomerID: 1001” once, store it in a central service, and use that same token everywhere. This is essential in a multi-platform environment.
- The Rule: The relationship must be 1:1. The masked value for a given real entity cannot vary, or your data fabric unravels.
What Are the Biggest Performance Challenges in Dynamic Data Masking?
Dynamic masking can increase query latency and affect execution plans, especially in large-scale analytical environments.
Research from IEEE shows
“DDM has a weak impact on query performance. This could be a powerful incentive for incorporating DDM in real-world software applications when up to 100GB data is stored using Oracle database server.” – IEEE
The convenience of real-time masking comes at a computational cost. The database can’t just read the raw value; it must execute a function to mask it for every row returned to an unauthorized user.
- Query Optimizer Confusion: When you mask a column used in a WHERE clause (e.g., WHERE masked_email LIKE ‘%@domain.com’), the database may not be able to use an index on that column efficiently, forcing slower full-table scans.
- Latency Spikes: The masking function adds overhead. In high-concurrency systems, this can compound. On X (Twitter), engineers have ranted about DDM introducing 400ms of latency per query, turning a snappy API into a sluggish mess.
- Mitigation: Use caching layers for masked results, implement masking at the application proxy level instead of the database for simple cases, and rigorously profile the performance impact of any DDM rule before deploying it broadly.
How Do Different Data Masking Techniques Compare?
Different masking methods offer varying levels of security, realism, reversibility, and operational complexity.
Choosing the right tool requires understanding the trade-offs. Here’s how the 6 major techniques stack up:
| Technique | Reversible? | Preserves Format? | Best For | Key Consideration |
| Substitution | No | Yes | Realistic test data (names, emails) | Lookup table maintenance |
| Shuffling | No | Yes | Analytics (salaries, ages) | Fails on small datasets |
| Variance | No | Yes | Trend analysis (dates, amounts) | Loses individual accuracy |
| Encryption | Yes | No | High-security storage/transit | Useless for application testing |
| Redaction | No | Partial | User displays (SSN, CC) | Destroys data utility |
| Nulling | No | No | Removing unused fields | Breaks NOT NULL constraints |
Adopting Secure Coding Practices means selecting the technique that provides the necessary security without breaking the intended functionality of the data.
FAQs
How do I choose between static data masking and dynamic data masking?
Use static data masking for development copies, while dynamic data masking protects sensitive data within active production environments.
Which industries benefit most from data masking compliance requirements?
Healthcare, finance, insurance, and retail organizations use GDPR data masking, HIPAA data masking, and PCI DSS masking regularly.
Can data masking work with unstructured files and documents?
Yes, document masking protects sensitive information within reports, spreadsheets, PDFs, emails, images, and other business records.
What are common challenges when implementing data masking solutions?
Organizations often struggle with maintaining data accuracy, preserving relationships, meeting compliance requirements, and minimizing performance impacts.
Is automated data masking better than manual data masking?
Automated data masking handles large datasets efficiently, while manual data masking works best for specialized review processes.
Final Thoughts on Data Masking
Data leaks often start in testing and development environments where sensitive information isn’t properly protected. That’s the reality. Choosing the right masking technique helps keep data useful while reducing unnecessary exposure across your systems.
Security isn’t a one-time task. As systems change, your protections should too. For developers who want practical security skills, the Secure Coding Practices Bootcamp offers hands-on training that helps teams build safer software. Join here: Secure Coding Practices Bootcamp
References
- https://www.lbtu.lv/sites/default/files/files/lapas/Survey_on_Priv-Pres_Techniques.pdf#12#1
- https://ui.adsabs.harvard.edu/abs/2023IEEEA..1118520F/abstract